
Pivot Tracing: Dynamic Causal Monitoring For Distributed Systems
- Posted by Jesse Polhemus
- on June 29, 2016
by Jonathan Mace, Ryan Roelke, and Rodrigo Fonseca
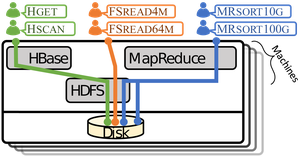
Pivot Tracing is a monitoring framework for distributed systems that can seamlessly correlate statistics across applications, components, and machines at runtime, without needing to change or redeploy system code. Users can define and install monitoring queries on-the-fly, to collect arbitrary statistics from one point in the system while being able to select, filter, and group by events meaningful at other points in the system. Pivot Tracing does not correlate cross-component events using expensive global aggregations, nor does it perform offline analysis. Instead, Pivot Tracing directly correlates events as they happen, by piggybacking metadata alongside requests as they execute – even across component and machine boundaries. This gives Pivot Tracing a very low runtime overhead – less than 1% for many cross-component monitoring queries.
This article was originally published in Conduit, the Brown CS magazine. To read the entire piece, click here and advance to page 36.
For more information, please click the link that follows to contact Brown CS Communication Outreach Specialist Jesse C. Polhemus.


